We have 3 papers accepted by ICLR 2026!
We have three papers accepted by ICLR 2026! One paper advances federated learning with a novel analytic deep framework that tackles data heterogeneity and efficiency challenges. Another introduces a promptable and interpretable evaluation agent for robotic manipulation, enabling fast and user-centric benchmarking without large-scale simulation. The third paper accelerates LLM inference through training-free sparse activation, offering both theoretical guarantees and strong empirical performance. More details are provided below.
Paper 1: DeepAFL: Deep Analytic Federated Learning
Authors: Jianheng Tang, Yajiang Huang, Kejia Fan, Feijiang Han, Jiaxu Li, Jinfeng Xu, Run He, Anfeng Liu, Houbing Herbert Song, Huiping Zhuang, Yunhuai Liu
Abstract:
Federated Learning (FL) is a popular distributed learning paradigm to break down data silo. Traditional FL approaches largely rely on gradient-based updates, facing significant issues about heterogeneity, scalability, convergence, and overhead, etc. Recently, some analytic-learning-based work has attempted to handle these issues by eliminating gradient-based updates via analytical (i.e., closed-form) solutions. Despite achieving superior invariance to data heterogeneity, these approaches are fundamentally limited by their single-layer linear model with a frozen pre-trained backbone. As a result, they can only achieve suboptimal performance due to their lack of representation learning capabilities. In this paper, to enable representable analytic models while preserving the ideal invariance to data heterogeneity for FL, we propose our Deep Analytic Federated Learning approach, named DeepAFL. Drawing inspiration from the great success of ResNet in gradient-based learning, we design gradient-free residual blocks in our DeepAFL with analytical solutions. We further introduce an efficient layer-wise protocol for training our deep analytic models layer by layer in FL through least squares. Both theoretical analyses and empirical evaluations validate our DeepAFL’s superior performance with its dual advantages in heterogeneity invariance and representation learning, outperforming state-of-the-art baselines by up to 5.68%–8.42% across three benchmark datasets. The related codes will be made open-sourced upon the acceptance of this paper.
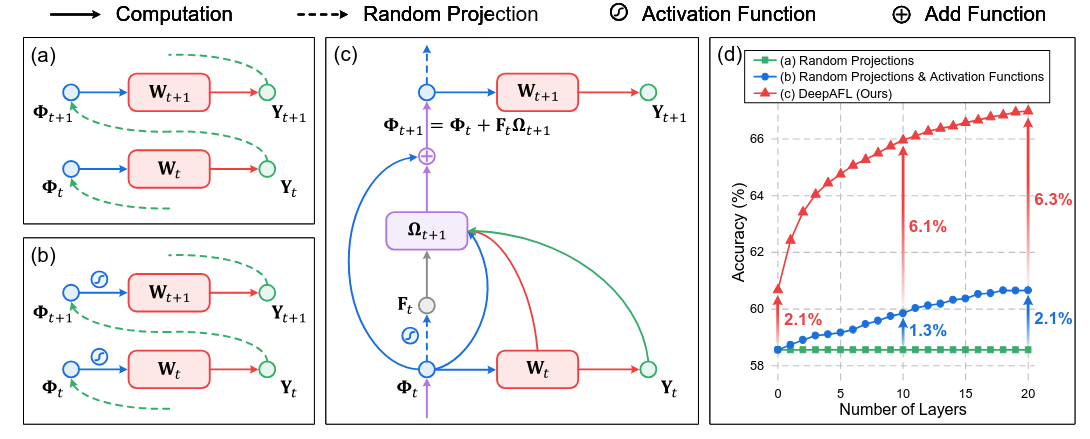
Comparing our proposed DeepAFL with the naive approaches for representation learning
Paper: https://openreview.net/pdf?id=ve3EzAvMGe
Paper 2: ManipEvalAgent: Promptable and Efficient Evaluation Framework for Robotic Manipulation Policies
Authors: Yiteng Chen, WenboLi, Shiyi Wang, Xiangyu Zhao, Huiping Zhuang, Qingyao Wu
Abstract:
In recent years, robotic manipulation policies have made substantial progress. However, evaluating these policies typically requires large-scale sampling in simulation benchmarks, leading to high time costs. Moreover, existing evaluation pipelines are usually fixed, do not account for user needs, and report only a single scalar score, lacking interpretability. In contrast, human experts can quickly form an intuitive impression of a policy’s capabilities from just a handful of executions. We therefore propose ManipEvalAgent, an efficient, promptable, and dynamically multi-round evaluation framework for robotic manipulation policies. The framework conducts small-batch, multi-round evaluations and adaptively plans subsequent evaluation steps based on intermediate observations from each round. Via code generation, it constructs tasks and evaluation functions within simulator. By generating evaluation functions and leveraging vision–language models (VLMs) for video understanding, ManipEvalAgent provides user-instruction-centric, fine-grained analysis. Our approach offers three key advantages: (1) efficiency, no need for massive sampling; (2) promptable, planning the evaluation process according to user queries; and (3) interpretability, providing diagnostic text that goes beyond a single score. Across multiple settings, our evaluation method significantly shortens the overall time compared with traditional simulation benchmarks, while reaching conclusions comparable to those from large-scale simulation benchmarks.
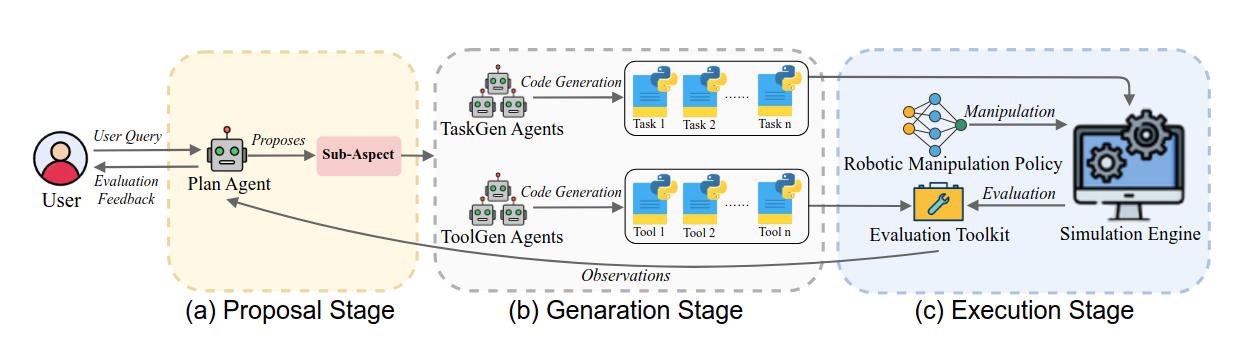
Overview of ManipEvalAgent framework
Paper: https://openreview.net/pdf?id=3u6AkbWEls
Paper 3: WINA: Weight Informed Neuron Activation for Accelerating Large Language Model Inference
Authors: Sihan Chen, Dan Zhao, Jongwoo Ko, Colby Banbury, Huiping Zhuang, Luming Liang, Pashmina Cameron, Tianyi Chen
Abstract:
The ever-increasing computational demands of large language models (LLMs) make efficient inference a central challenge. While recent advances leverage specialized architectures or selective activation, they typically require (re)training or architectural modifications, limiting their broad applicability. Training-free sparse activation, in contrast, offers a plug-and-play pathway to efficiency; however, existing methods often rely solely on hidden state magnitudes, leading to significant approximation error and performance degradation. To address this, we introduce WINA (Weight-Informed Neuron Activation): a simple framework for training-free sparse activation that incorporates both hidden state magnitudes and weight matrix structure. By also leveraging the ℓ2-norm of the model’s weight matrices, WINA yields a principled sparsification strategy with provably optimal approximation error bounds, offering better and tighter theoretical guarantees than prior state-of-the-art approaches. Overall, WINA also empirically outperforms many previous training-free methods across diverse LLM architectures and datasets: not only matching or exceeding their accuracy at comparable sparsity levels, but also sustaining performance better at more extreme sparsity levels. Together, these results position WINA as a practical, theoretically grounded, and broadly deployable solution for efficient inference. Our source code is anonymously available at https://anonymous.4open.science/r/wina-F704/README.md.
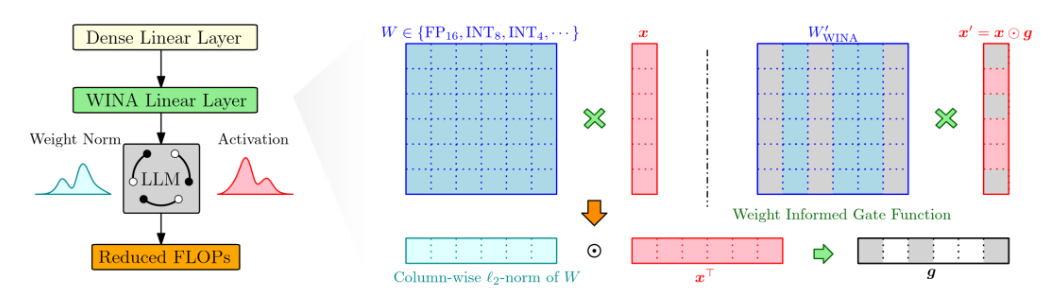
Overview of WINA