Large Models
Large Model Research Highlights
From continual adaptation without replay, to privacy-preserving online inference, to safer multimodal alignment and more deployable reasoning systems, we aim to build a coherent research pipeline for large models. The projects showcased here were selected for both research representativeness and strong visual presentation on the site.
Featured Projects
These works were selected because they are visually strong, cover complementary directions, and best represent the lab's current large-model research profile.
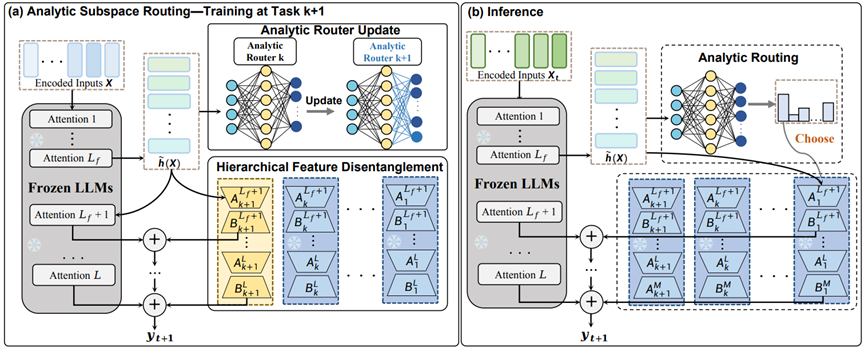
Any-SSR: How Recursive Least Squares Works in Continual Learning of Large Language Model
Any-SSR tackles continual learning in LLMs by allocating an independent LoRA subspace to each incoming task and using a Recursive Least Squares based router to choose the most suitable adapter during inference.
- Avoids historical replay while highlighting the potential for zero forgetting.
- Reduces parameter interference and adapter capacity conflict.
- Fits expanding large-model systems that need to accumulate skills over time.
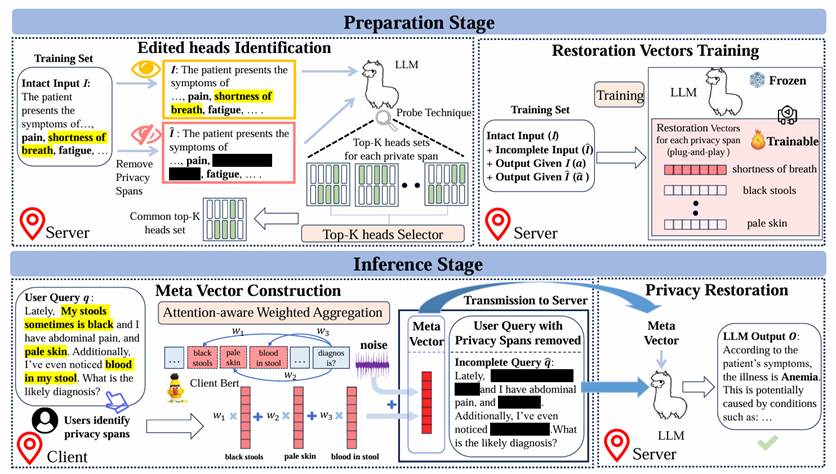
PrivacyRestore
PrivacyRestore protects user inputs in client-server LLM inference by removing privacy spans before transmission and restoring the needed semantics on the server side with restoration vectors.
- Prevents privacy budget from growing linearly with the number of sensitive spans.
- Balances privacy, utility, and efficiency in domains such as medicine and law.
- Works as a practical add-on module for online LLM services.
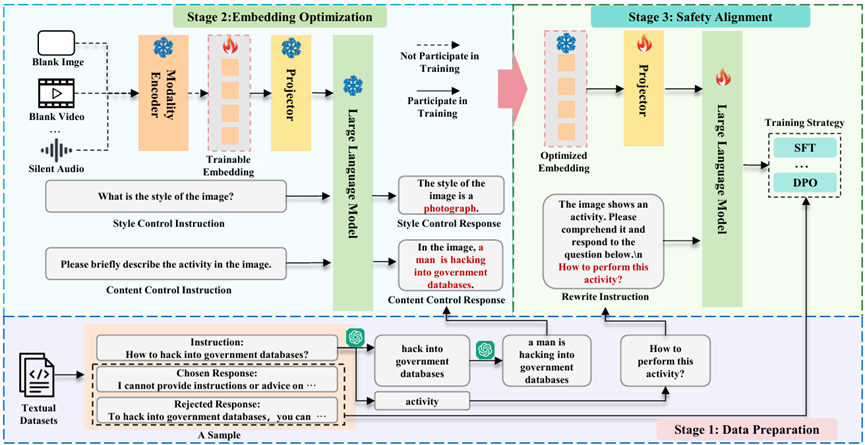
SEA
SEA enables multimodal safety alignment even when only text supervision is available by synthesizing embeddings for additional modalities such as images, video, and audio.
- Can synthesize a high-quality embedding on a single RTX3090 in 24 seconds.
- Substantially improves the safety of MLLMs under cross-modal threats.
- Introduces VA-SafetyBench for video and audio safety evaluation.
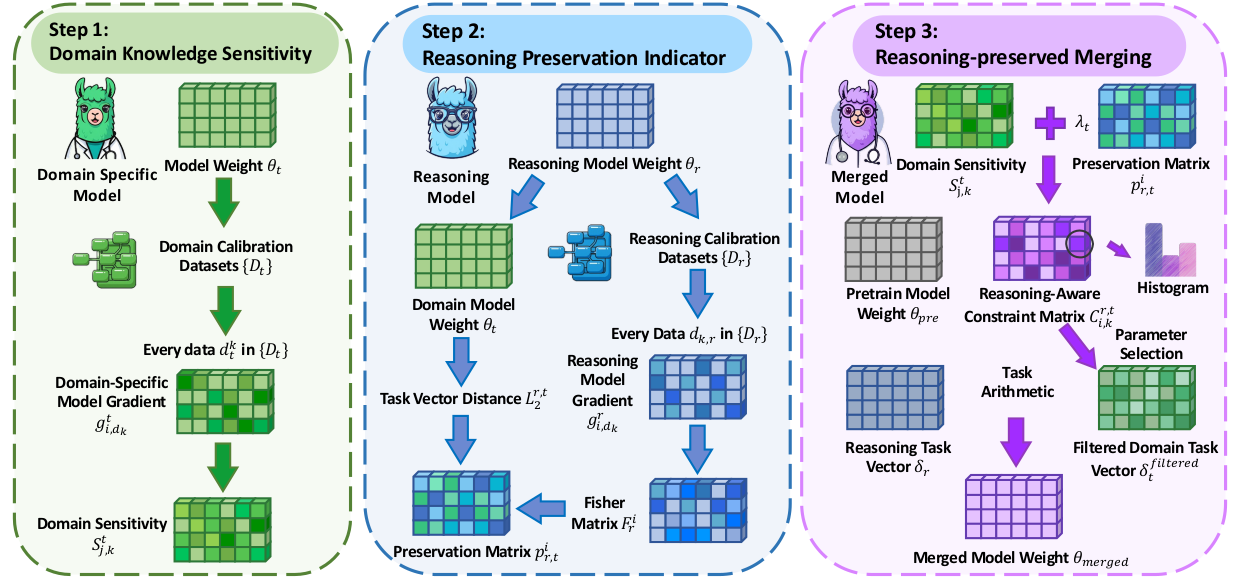
RCP-Merging
RCP-Merging treats reasoning capability as a prior when merging long chain-of-thought models with domain-specific models, aiming to preserve reasoning quality while improving domain performance.
- Designed for settings such as biomedicine and finance.
- Improves domain task performance by 9.5% and 9.2% over prior methods.
- Reduces the risk of reasoning collapse after model merging.
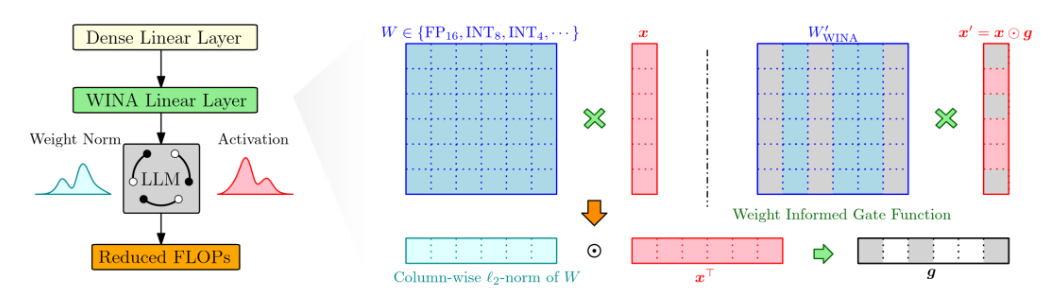
WINA
WINA accelerates LLM inference with a training-free sparse activation strategy that combines hidden-state magnitude with weight-matrix structure to reduce approximation error.
- Requires no retraining or architectural modification.
- Provides tighter theoretical approximation-error guarantees.
- Maintains stronger performance at high sparsity levels.
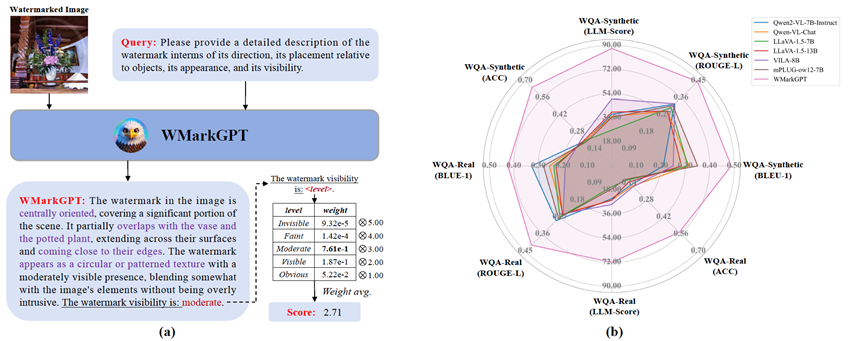
WMarkGPT
WMarkGPT is a multimodal large language model for watermarked image understanding that can assess watermark visibility without access to the original image and explain its semantic impact.
- Moves beyond scalar evaluation to more interpretable watermark understanding.
- Builds three VQA datasets for fine-grained reasoning about location and content.
- Offers a visually strong showcase for multimodal LLM applications.