持续学习
在持续学习领域,团队开创了一个全新的分支:解析持续学习。采用传统机器学习方法,利用最小二乘递归的扩展式递归推导,实现条件完全无遗忘特性的新型持续学习框架。近2年已在此分支发表超15篇CCF-A顶会。
我们提出一种全新的类增量学习(CIL)方法,同时攻克灾难性遗忘与数据隐私两大难题。所提出的解析类增量学习(ACIL)框架无需保存任何历史数据即可实现旧知识的绝对记忆,从而确保数据隐私。理论上,我们证明 ACIL 仅利用当前数据即可获得与传统联合训练完全一致的结果。实验结果表明,ACIL 在 25 与 50 等多阶段场景下均显著优于现有最佳方法。
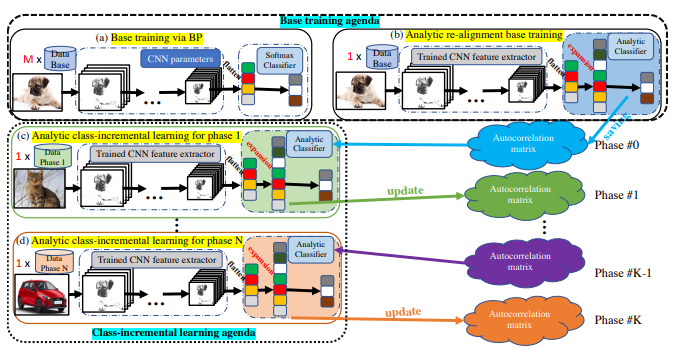
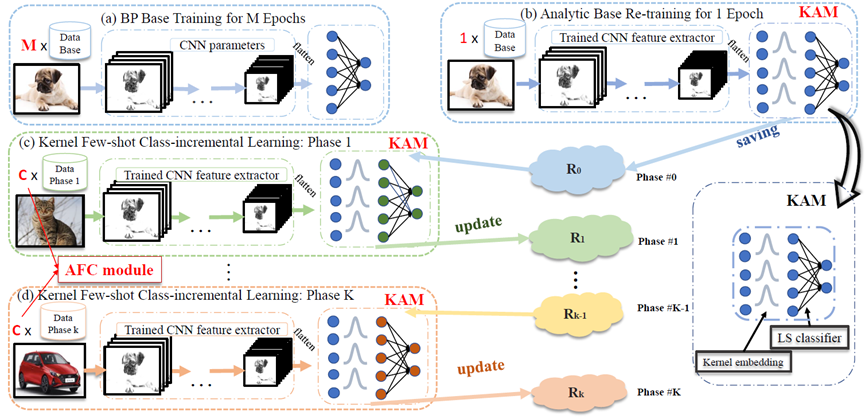
本文聚焦小样本类增量学习(FSCIL),并将解析类增量学习(ACIL)拓展至该领域。为应对小样本挑战,我们提出基于高斯核的核解析模块,以递归解析方式实现 FSCIL,并引入增强特征拼接模块来平衡旧任务与新任务的偏好。我们的方法在多个数据集上均达到当前最优性能。
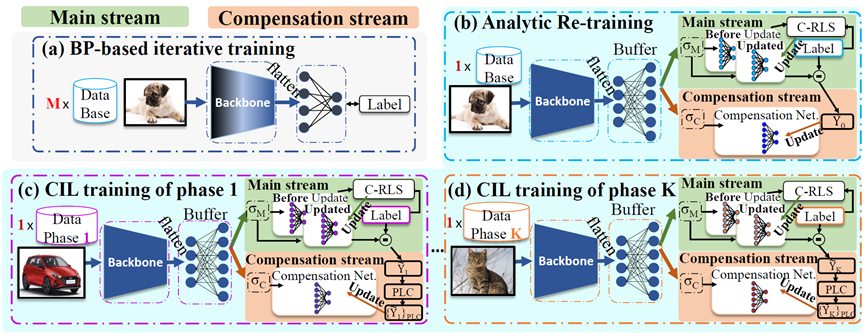
本文关注解析持续学习中线性分类器欠拟合的问题。为提升拟合性能,我们提出一种用于类增量学习的双流结构。主流将类增量学习(CIL)问题重新定义为级联递归最小二乘(C-RLS)任务,从而在 CIL 与其联合训练对应之间建立等价关系。补偿流由双激活补偿(DAC)模块驱动,该模块采用与主流不同的激活函数重新激活嵌入,并将嵌入投影到主流线性映射的零空间,以寻求额外的拟合补偿。通过引入双流结构,我们的方法显著改善了拟合效果,并在与现有 CIL 方法的对比中取得更优性能。
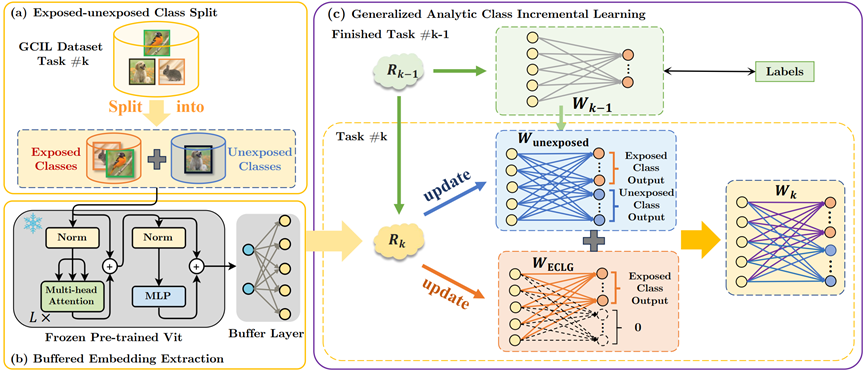
广义类增量学习(GCIL)面向更贴近现实的持续学习场景,其中新到达的数据混杂着多种类别,且样本规模分布未知。本文提出一种无需样本保存的 GCIL 方法——广义解析持续学习(GACL),将解析学习思想拓展至 GCIL 场景。该方法通过将新数据分解为已暴露类与未暴露类,获得权重不变性——这一罕见却宝贵的性质,使得增量学习与联合训练在结果上等价。在 GCIL 环境下,这一等价性尤为关键,因为不同任务间的数据分布差异不再构成挑战。实验表明,GACL 在多种数据集和 GCIL 设定下始终取得领先性能。
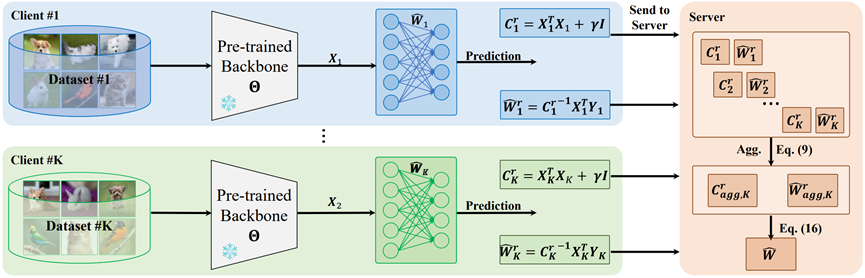
本文在联邦学习场景下,通过“解析学习的双分支利用”实现了对数据划分的完全不变性。所提出的 AFL 方法借鉴解析学习——一种无需梯度的技术,可在单轮前向计算中以解析解训练神经网络。在本地客户端训练阶段,AFL 仅需一轮即可完成训练,彻底摆脱多轮迭代需求;在聚合阶段,我们推导出绝对聚合(AA)法则,仅需一次通信即可收敛,显著降低通信开销并实现快速收敛。更重要的是,AFL 展现出“数据划分不变性”:无论完整数据集如何在各客户端间分布,聚合结果始终一致。这一特性带来了对数据异构性与客户端数量变化的天然鲁棒性。我们在多种联邦学习设定下进行实验,包括极端非独立同分布场景及大量客户端(例如 1000 个)情形,AFL 在所有设定中均保持强劲竞争力。