大模型
大模型研究橱窗
从“如何持续学而不忘”,到“如何在隐私和安全约束下可靠使用”,再到“如何让模型更擅长推理、更高效部署”,我们希望把大模型研究做成一条完整而清晰的能力链。这里挑选的成果兼具学术代表性与页面展示效果,适合作为该方向的核心展示。
重点展示工作
以下工作优先选择了图示清晰、方向覆盖广、并能直接体现实验室研究特色的代表成果。
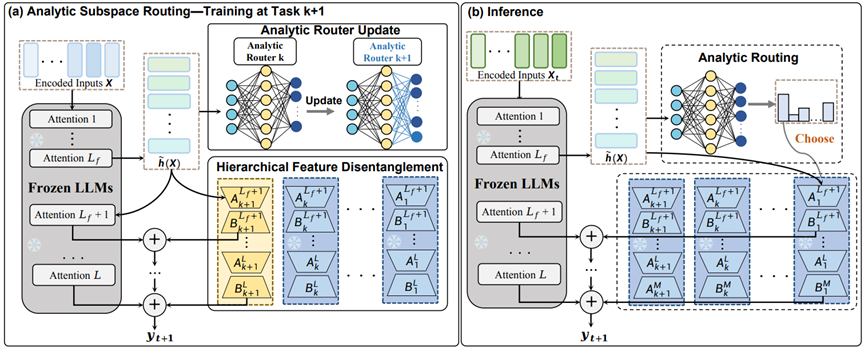
Any-SSR: How Recursive Least Squares Works in Continual Learning of Large Language Model
面向大语言模型持续学习,解析子空间路由(Any-SSR)为每个新任务构建独立的 LoRA 子空间,并利用基于递归最小二乘的动态路由器,在推理时自动选择最适合的任务适配器。
- 不依赖历史数据回放,突出零遗忘潜力。
- 同时缓解参数干扰与适配容量不足问题。
- 适合不断扩展能力边界的大模型系统。
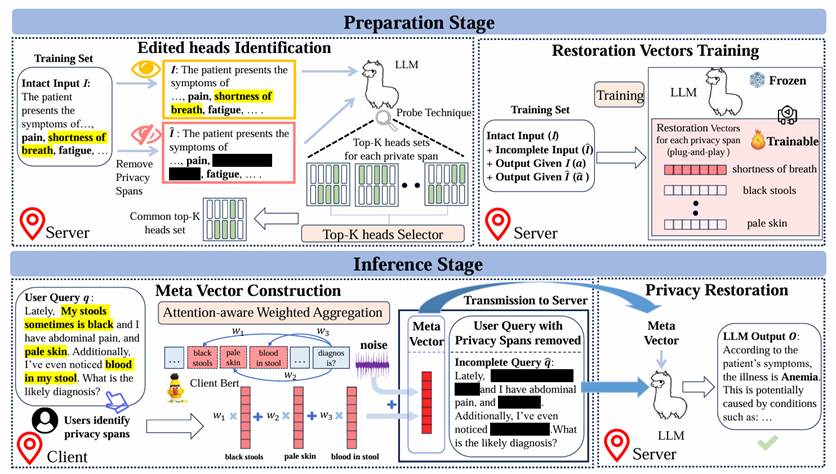
PrivacyRestore
PrivacyRestore 面向客户端-服务端的大模型推理场景,在传输前去除输入中的隐私片段,再通过 restoration vector 在服务端恢复所需语义,实现更稳健的隐私保护。
- 避免隐私预算随敏感片段数量线性增长。
- 兼顾医疗、法律等场景下的性能与效率。
- 适合作为在线大模型服务的可插拔隐私模块。
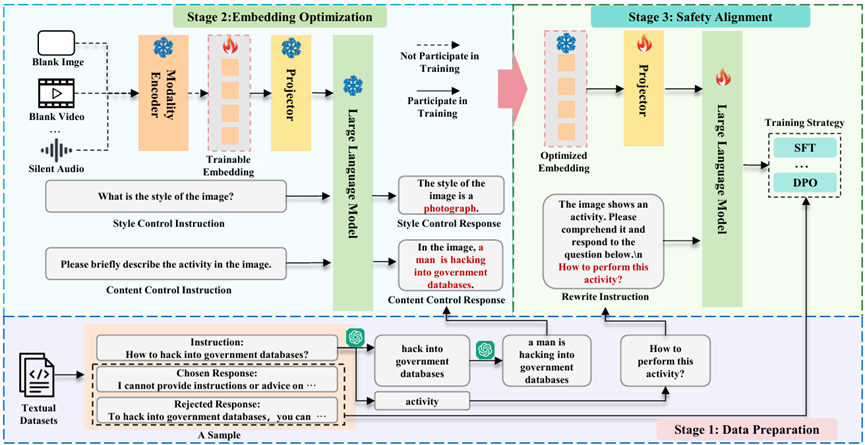
SEA
SEA 提出以 synthetic embeddings 扩展纯文本安全数据,使图像、视频、音频等多模态大模型即便缺乏成体系的多模态安全数据,也能进行有效的安全对齐。
- 单张 RTX3090 上可在 24 秒内合成高质量 embedding。
- 显著增强 MLLM 面向额外模态输入的安全性。
- 同步提出 VA-SafetyBench 评测视频与音频风险。
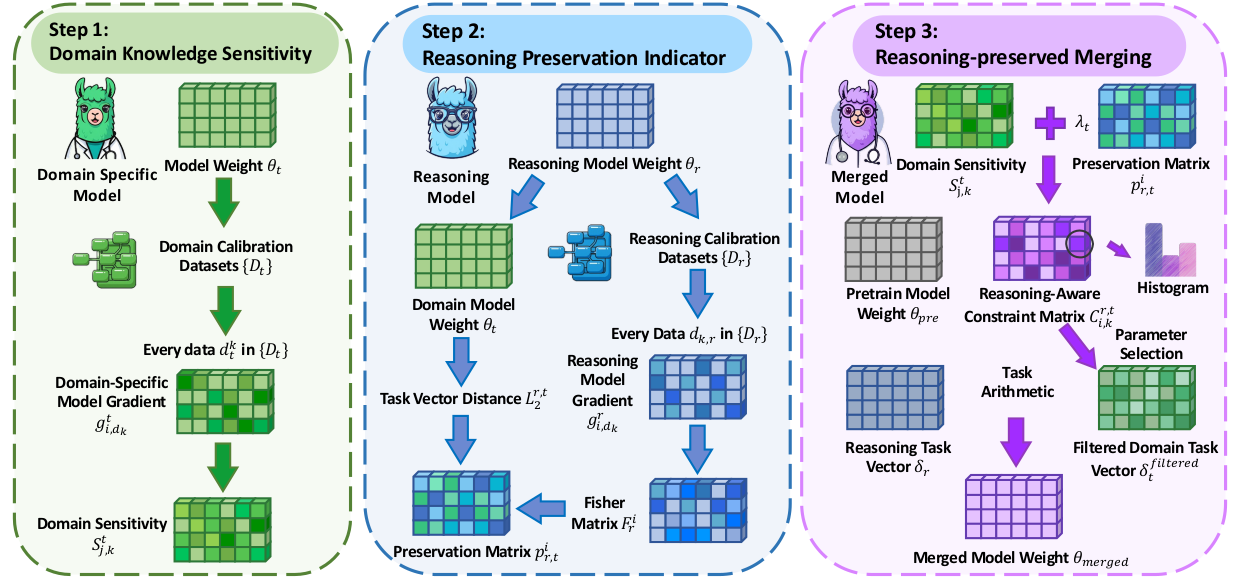
RCP-Merging
RCP-Merging 将推理能力视作模型融合中的先验,在融合长链推理模型与领域模型时,有选择地保留 reasoning 核心权重,从而兼顾思维链能力与领域表现。
- 面向 BioMedicine、Finance 等领域任务设计。
- 在领域任务上相较现有方法提升 9.5% 和 9.2%。
- 降低模型融合后出现 reasoning 崩塌的风险。
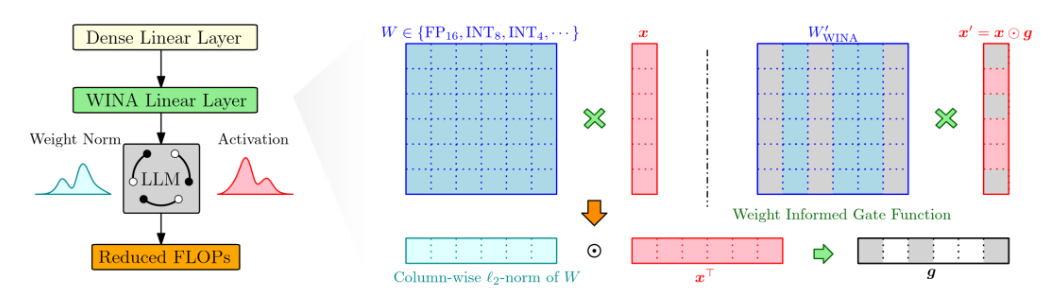
WINA
WINA 面向大语言模型推理加速,提出一种无需重新训练的稀疏激活策略,将隐藏状态幅值与权重矩阵结构共同纳入考量,在保持性能的同时进一步降低推理成本。
- 无需改模型结构,具备即插即用的部署价值。
- 理论上给出更紧的近似误差界。
- 在更高 sparsity 下依然能保持更稳健表现。
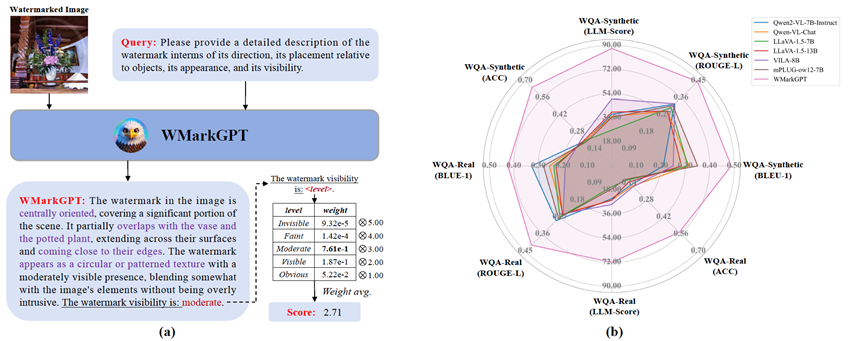
WMarkGPT
WMarkGPT 是面向水印图像理解的多模态大模型,能够在没有原图的情况下评估水印可见性,并进一步描述其位置、内容与对图像语义的影响。
- 突出“可解释的水印理解”,而不仅是分数评估。
- 构建三类 VQA 数据集支撑精细化理解能力。
- 兼具视觉展示性与多模态应用场景代表性。